Production-grade web scraping API with auto-escalating fetcher modes (fast HTTP, headless browser, stealth), structured data extraction, multi-page crawling, screenshot capture, PDF generation, and AEO360 SEO audits.
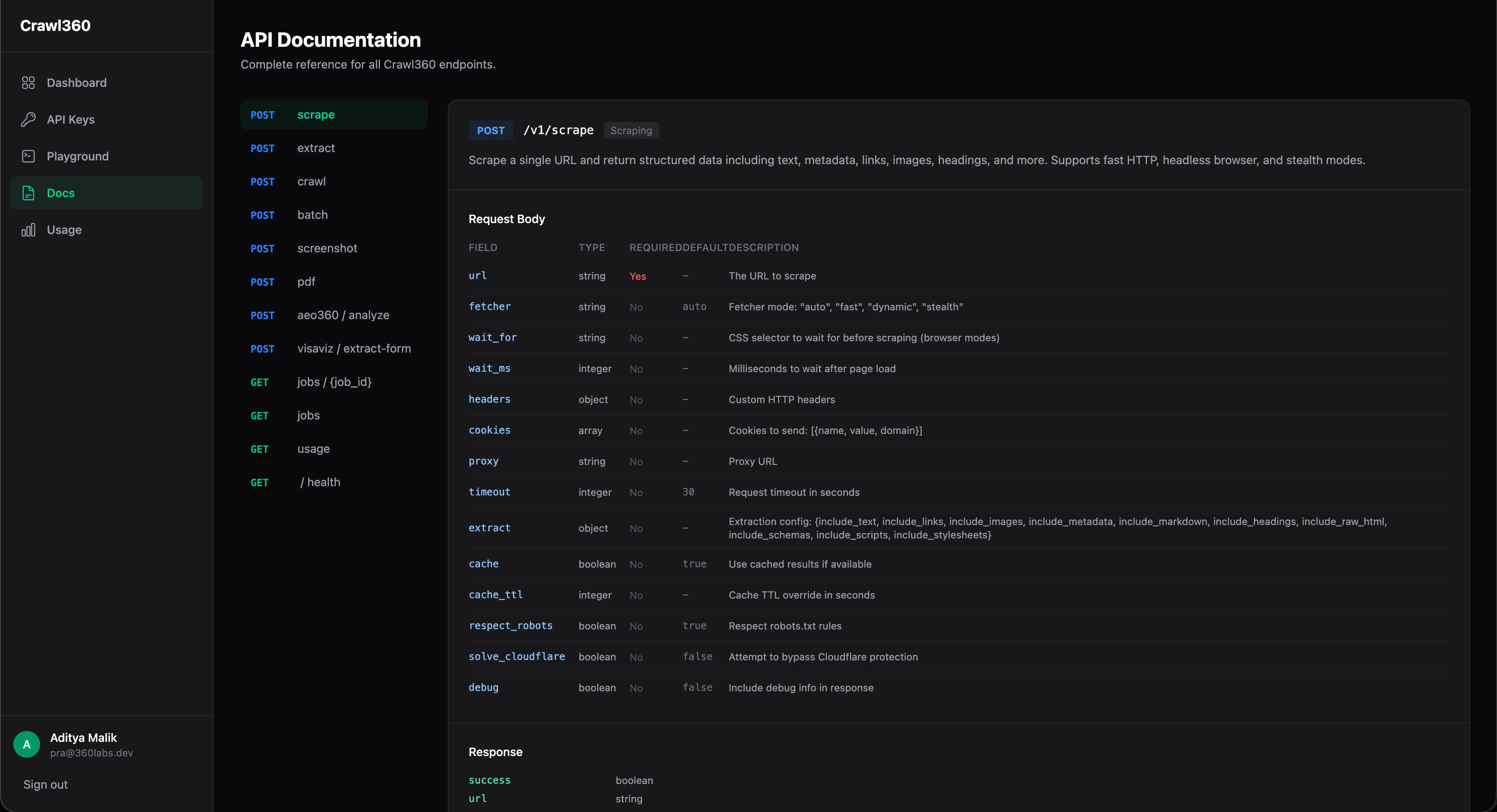
One API, seven capabilities. Single-page scrape with auto-escalating fetcher (fast > dynamic > stealth). CSS/XPath structured extraction. Multi-page crawl (up to 50 pages, 5 levels deep) with async job polling and webhooks. Screenshot capture (PNG/JPEG, full-page). PDF generation (A4/Letter/Legal). AEO360 full-site SEO audit. Batch scraping up to 100 URLs in parallel. Cloudflare bypass, proxy support, robots.txt compliance, and response caching built in.
SCRAPER PIPELINE
Let's discuss how this can work for you.
Get in Touch →